Subsets
In Hold'em poker, there's a total of 1755 possible unique flops.
When creating a database for different flops, ideally, one would extensively need to include every single one of these flops.
The disadvantage here would be that processing a database of 1755 flops would require considerable computation time.
In order to get around this, GTO+ offers several standard weighted subsets.
These subsets are smaller sets of flops that represent the total possible number of 1755 flops as closely as possible.
Currently subsets are available for the following numbers of flops: 15,19,23,33,37,44,55,66,80,89,111,129,141,163.
Performance of the subsets
The subsets have been designed to be of the highest possible quality. Although we cannot say for certain whether significant improvement is possible, we believe that — within reason — our subsets are close to optimal.
To test them, we created several different test cases: top 30% vs top 30%, top 30% vs bottom 52%, and bottom 37% vs bottom 52%.
For each test case, four separate full databases of all 1,755 flops were created, each using a different stack-to-pot ratio ranging from shallow to deep.
This resulted in 12 different test files for each subset.
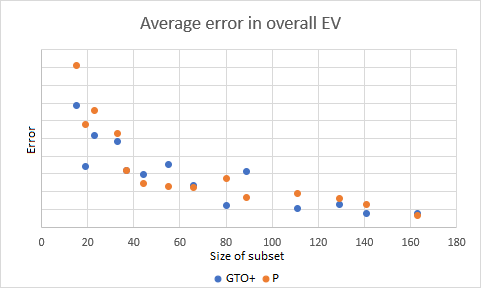
The plot below shows the average error per hand versus the size of the subset.
Roughly, this error scales as f(x) = 1 / x — in other words, doubling the subset size roughly halves the error.
We were fortunate to have subsets available from a third party (the name starts with “p”) against which we could compare our own.
In the situations we tested, GTO+ appeared to outperform the third party slightly, but consistently.
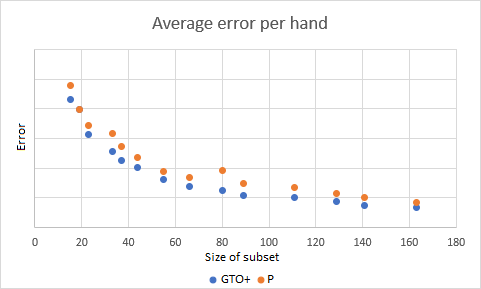
In this case GTO+ is better 9 times and worse 5 times.